
Python with the beautifulsoup library makes it very easy for beginners to scrape data from any HTML website. I have been using the request library with python to scrape data from multiple websites. It works like a charm every time unless you encounter a website that renders the front end with javascript.
Data scraping helps to collect data from websites. There are various free and paid tools to scrape data from the web, but they have their limitations. In the beginning, I used octoparse to scrape data from websites. It didn’t take long to realize its limitations. That is where I moved on to python and beautifulsoup, later switched to lxml, selenium, and puppeteer for advanced scraping.
Python and its libraries helped me overcome the initial limitations and ultimately became my preferred tool of the trade to scrape data without any limitations.
So why python?
- Python is very simple to code. The syntax is similar to writing English, so it is easily understandable. Unlike most other languages, there is no need to use the semicolon after the end of every line. It also gives away with the parenthesis. This makes the code look much cleaner.
- Python has a vast library that comes in handy to refine the extracted data.
- Python has come a long way and so has its community. If you face any problem with your code, you can expect a solution somewhere on the internet. ( Ex: Stackoverflow is just a search away )
In this tutorial, I will show you how to scrape an HTML website with python and beautifulsoup. Before we move on, let’s install the prerequisites.
What is required to scrape web data with Python:
- Python
- BeautifulSoup4
You will need to install python and beautifulsoup. Although there are other libraries like lxml and scrapy, beautifulsoup is the best when it comes to ease of learning. I am assuming you are using windows. Here is how you can install both.
Installing Python on Windows
Download Python from the Official Python downloads page. I will recommend downloading the 64 bit installer.
Once downloaded, right-click on the python installer and select run as administrator.
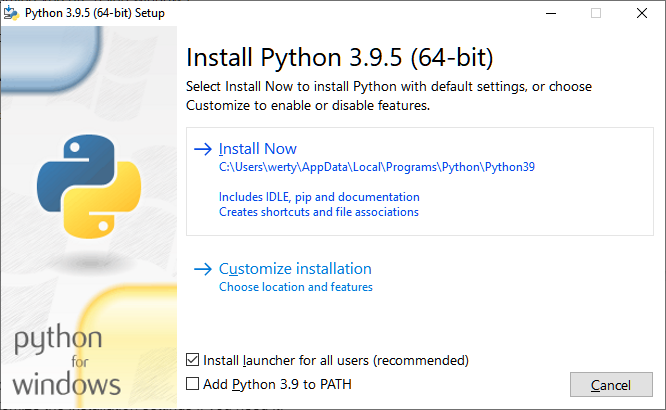
By default, the python installer will install python with default settings. There is an option to customize the installation settings if you need it.
Installing Requests
We have to install the Requests library. This library fetches the HTML code of a website through a HTTP request and store it as an object. This object can be then passed on to beautifulsoup for parsing.
Open the command prompt in windows. Then type the following and press enter to install the Requests library on your computer.
pip3 install requestsInstalling BeautifulSoup
The BeautifulSoup library is not installed with Python by default. It has to be installed manually, which is a simple task. Here’s how you can install the BeautifulSoup library for python in windows.
Open the command prompt in windows. Then type the following and press enter to install the BeautifulSoup library on your computer.
pip3 install beautifulsoup4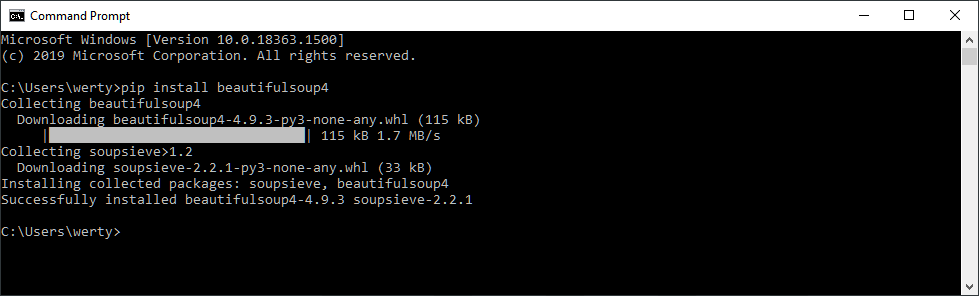
The BeautifulSoup library for python is now installed on your computer. Now we can move on to writing the code for the web scraper.
Installing Pandas
We will install the pandas library and use it to save the scraped data to a CSV file. The following code will install Pandas.
pip3 install pandasWriting the code
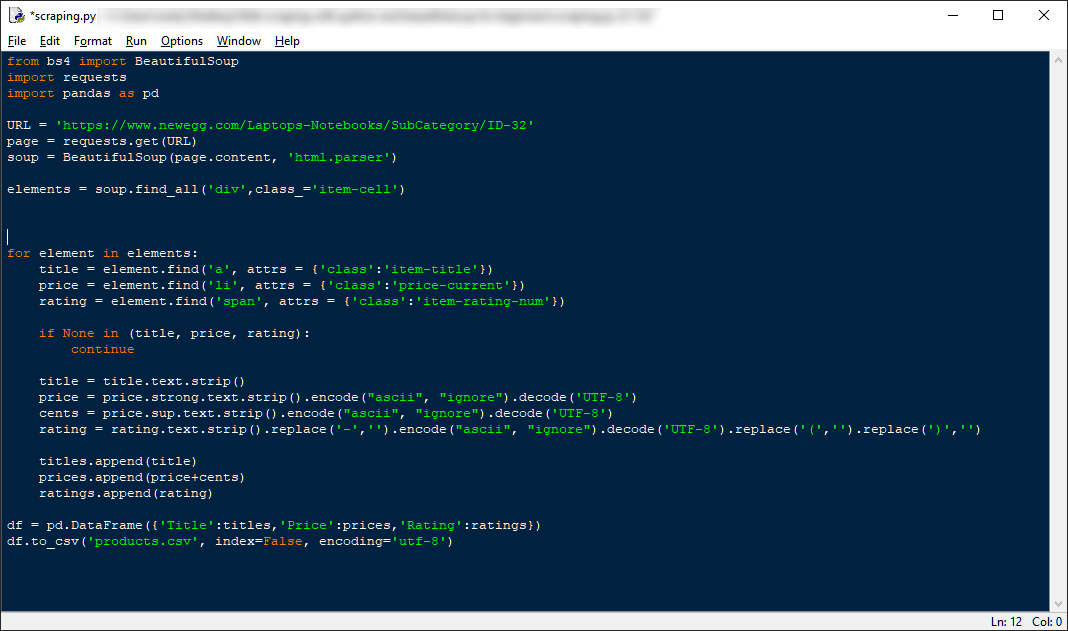
I assume you have a site in your mind from which you want to scrape data from. For this tutorial, we will be scraping the prices of laptops from Newegg on this page:
https://www.newegg.com/Laptops-Notebooks/SubCategory/ID-32
Step 1: Importing libraries
In python, we have to import the required libraries first. For this tutorial, we will need the requests and BeautifulSoup library. We can import them with the following code:
from bs4 import BeautifulSoup
import requests
import pandas as pdStep 2: Fetching the HTML code of a website.
We will make a HTTP request with the requests library to fetch the HTML code of the website and stores it as an object.
URL = 'https://www.newegg.com/Laptops-Notebooks/SubCategory/ID-32'
page = requests.get(URL)You can pass an additional header parameter for the HTTP request. This will help to disguise the HTTP request and make it look like the request is originating from a browser instead of a script. That is something we will learn in a more advanced tutorial about web scraping.
Step 3: Parsing the HTML code
Next, we pass the HTML code to the BeautifulSoup library for parsing.
soup = BeautifulSoup(page.content, 'html.parser')
As you can see, there are around 36 laptops being displayed on the page. If we inspect the HTML code through the developer tools, we can see the product data is inside the div element with the item-cell class. So we have to select all these div elements and then iterate through them to get the product details.
To select all the div elements with the item-cell class with BeautifulSoup, we can use the following code.
elements = soup.find_all('div',class_='item-cell')Next, we will declare arrays that will store the details from the scraped data.
titles=[]
prices=[]
ratings=[]Step 4: Finding elements by their id and class
We can now find elements in the HTML code through their id or class. If you are familiar with HTML, you should know that ids are always unique and can only be used once. Classes on the other hand are not unique and can be used multiple times.
So it is always easier to find elements by their ids wherever possible. In our case, we can use classes as there are no ids used for the data that needs to be scraped.
Now, let’s iterate through the products list and get the product details like the title, price, and rating details of each product.
for element in elements:
title = element.find('a', attrs = {'class':'item-title'})
price = element.find('li', attrs = {'class':'price-current'})
rating = element.find('span', attrs = {'class':'item-rating-num'})In case any of the above details are returned none or null, we will use the following code to skip the errors and prevent the web scraping script from stopping.
if None in (title, price, rating):
continueStep 5: Cleaning the details
The extracted data will have blank spaces and other unwanted characters. We need to remove these in order to get the final cleaned output.
- The strip function removes any unwanted spaces before and after the extracted data.
- The encode(“ascii”, “ignore”) function ignores any unwanted characters such as .
- The decode(‘UTF-8’) function then decodes the text data into UTF-8 character encoding.
- The replace() function is used to remove brackets from the rating string.
title = title.text.strip()
price = price.strong.text.strip().encode("ascii", "ignore").decode('UTF-8')
cents = price.sup.text.strip().encode("ascii", "ignore").decode('UTF-8')
rating = rating.text.strip().replace('-','').encode("ascii", "ignore").decode('UTF-8').replace('(','').replace(')','')We need to append the cleaned data to the respective arrays so we can save them to a CSV file using the pandas library.
titles.append(title)
prices.append(price+cents)
ratings.append(rating)Step 6: Storing the scraped data to a csv file
Finally, we save the scraped data to a CSV file with the respective headers.
df = pd.DataFrame({'Title':titles,'Price':prices,'Rating':ratings})
df.to_csv('products.csv', index=False, encoding='utf-8')Here is the full code for the scraper:
from bs4 import BeautifulSoup
import requests
import pandas as pd
URL = 'https://www.newegg.com/Laptops-Notebooks/SubCategory/ID-32'
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
elements = soup.find_all('div',class_='item-cell')
for element in elements:
title = element.find('a', attrs = {'class':'item-title'})
price = element.find('li', attrs = {'class':'price-current'})
rating = element.find('span', attrs = {'class':'item-rating-num'})
if None in (title, price, rating):
continue
title = title.text.strip()
price = price.strong.text.strip().encode("ascii", "ignore").decode('UTF-8')
cents = price.sup.text.strip().encode("ascii", "ignore").decode('UTF-8')
rating = rating.text.strip().replace('-','').encode("ascii", "ignore").decode('UTF-8').replace('(','').replace(')','')
titles.append(title)
prices.append(price+cents)
ratings.append(rating)
df = pd.DataFrame({'Title':titles,'Price':prices,'Rating':ratings})
df.to_csv('products.csv', index=False, encoding='utf-8')
That’s it, you can now run the code and the scraped data will be saved in the same folder in the products.csv file.
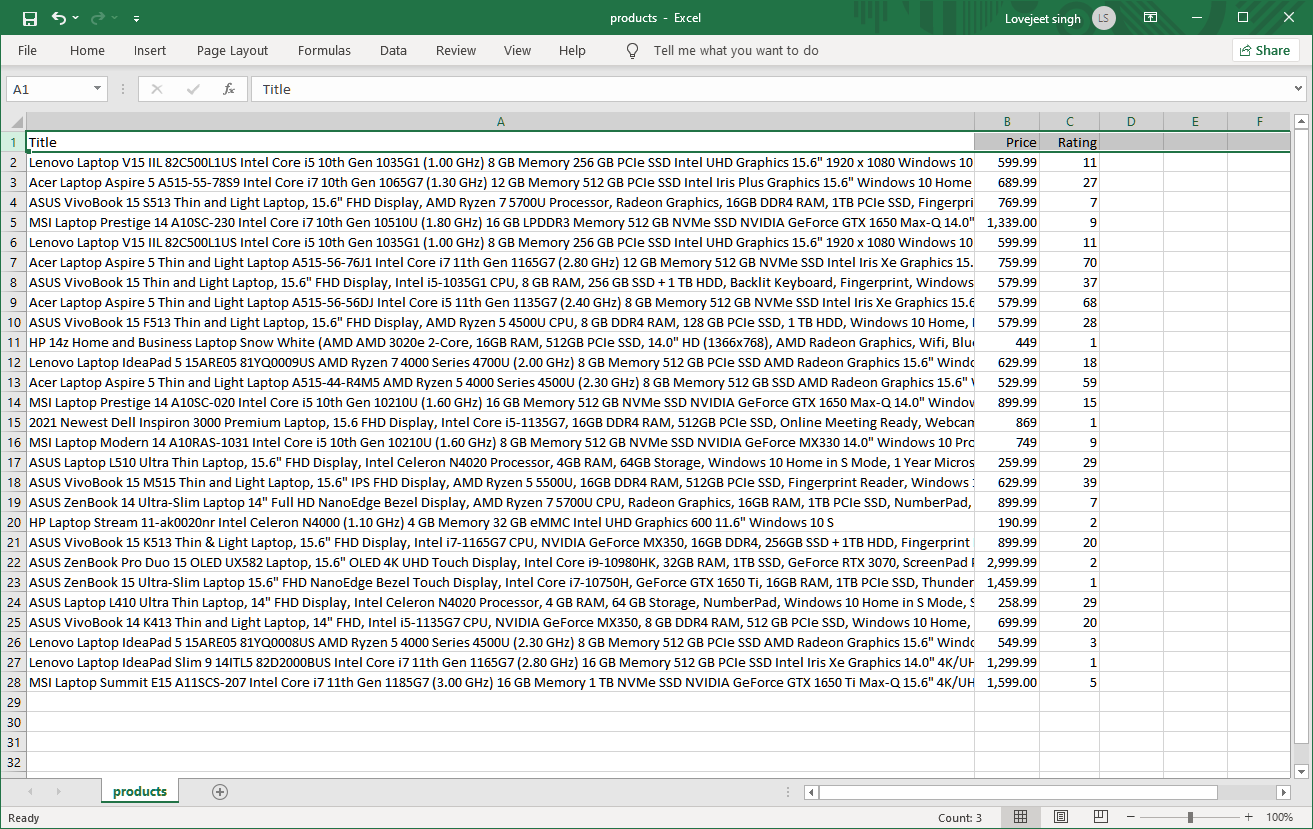
In the next tutorial, we will dive deep into advanced features of python and use the lxml library to create a robust web scraper. Till then let me know if you have any inputs on improving the current web scraper.

